ChatGPT
ChatGPT  Perplexity
Perplexity  Gemini
Gemini  Claude AI
Claude AI I remember feeling frustrated with Bedrock after the initial excitement wore off. We had the power of LLM - but it was isolated in a box and without any infrastructure to bring it to scale. Building agents boiled down to writing an extensive chain of if-else conditions into the model’s prompt. It was like a car without wheels.
Today, in early 2026, we finally have the wheels, and we might not have the brakes.
If you are confused by the sudden explosion of the term "Agent" in the AWS ecosystem like Bedrock Agents, Strands Agent, and AgentCore - you are not alone. The documentation makes them look like alternatives. They are not. They are evolutionary steps into bringing Agents into Production.
We are entering a period where traditional software architecture is falling behind the pace of AI development. To make sense of where we are, we need to step back and see how it started.

Stage 1: The Dawn of AI (Bedrock)
It's late 2023, Amazon realises they have fallen behind in the AI race, OpenAI just got valued at $30 Billion dollars. Amazon decides not to create another model to compete, but instead to build a platform. They thought what if a single API would be able to invoke any of these models, making it easy to integrate into your SaaS product in the AWS ecosystem.
Enter Bedrock - Bedrock gave developers the ease to directly add LLM capabilities into their existing systems.
import { BedrockRuntimeClient, InvokeModelCommand } from "@aws-sdk/client-bedrock-runtime";
//Initialise Bedrock Client
const client = new BedrockRuntimeClient({ region: "us-east-1" });
//Select Model and load parameters
const generateResponse = async (prompt: string) => {
const params = {
modelId: "anthropic.claude-3-haiku-20240307-v1:0",
body: JSON.stringify({
anthropic_version: "bedrock-2023-05-31",
max_tokens: 300,
temperature: 0.1,
top_p: 0.4,
top_k: 250,
messages: [
{ role: "user", content: [{ type: "text", text: prompt }] }
],
}),
};
try {
const response = await client.send(new InvokeModelCommand(params));
const body = JSON.parse(new TextDecoder().decode(response.body));
console.log(body.content[0].text);
} catch (err) {
console.error("Invocation failed:", err);
}
};
That's all you need to integrate LLM capabilities into your system. But in just a short span of 2 years, the amount of change in the AI space has made pretty much any code written using the initial Bedrock SDK released in Sept 2023 redundant.
But here's the major drawback, I wasn't just calling an API; I was hard-coding the specific request structure (anthropic_version, messages array format) that Claude required. If I had wanted to switch to Llama 2, I would have had to rewrite this entire object structure.
Prompts were incredibly verbose, prompt engineering was said to be the next big career opportunity.
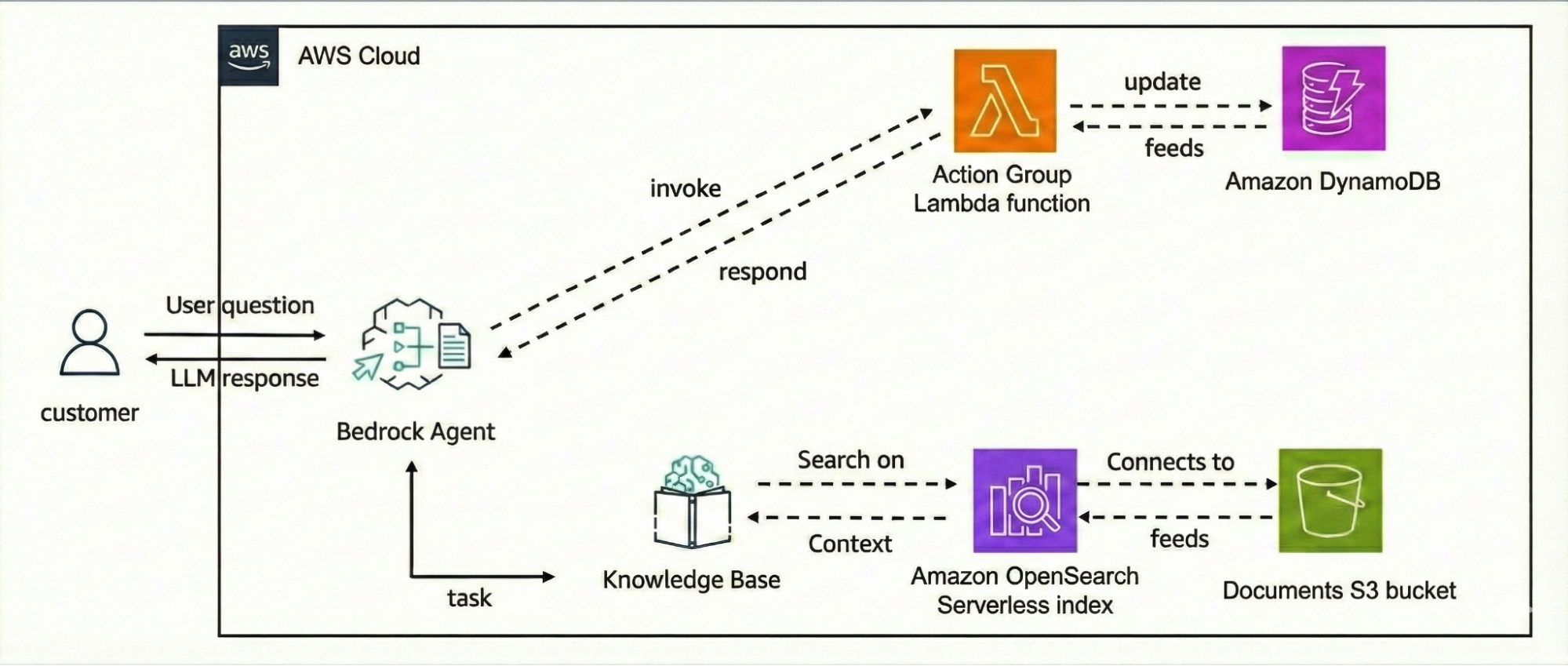
The only other way your model could get context about your application was with RAG! This was the buzzword around 2023/2024. AWS KnowledgeBase became a huge hit and every model had its own integration to some sort of vector store. Lambda functions invoking Bedrock with an integration to KnowledgeBase was a common architecture pattern.
But what if you wanted your model to interact with external systems? - That was possible with action groups. Specify a Lambda function that will be invoked based on the action group identified by the Foundation model during orchestration.
Stage 2: Democratising AI (Bedrock Converse API)
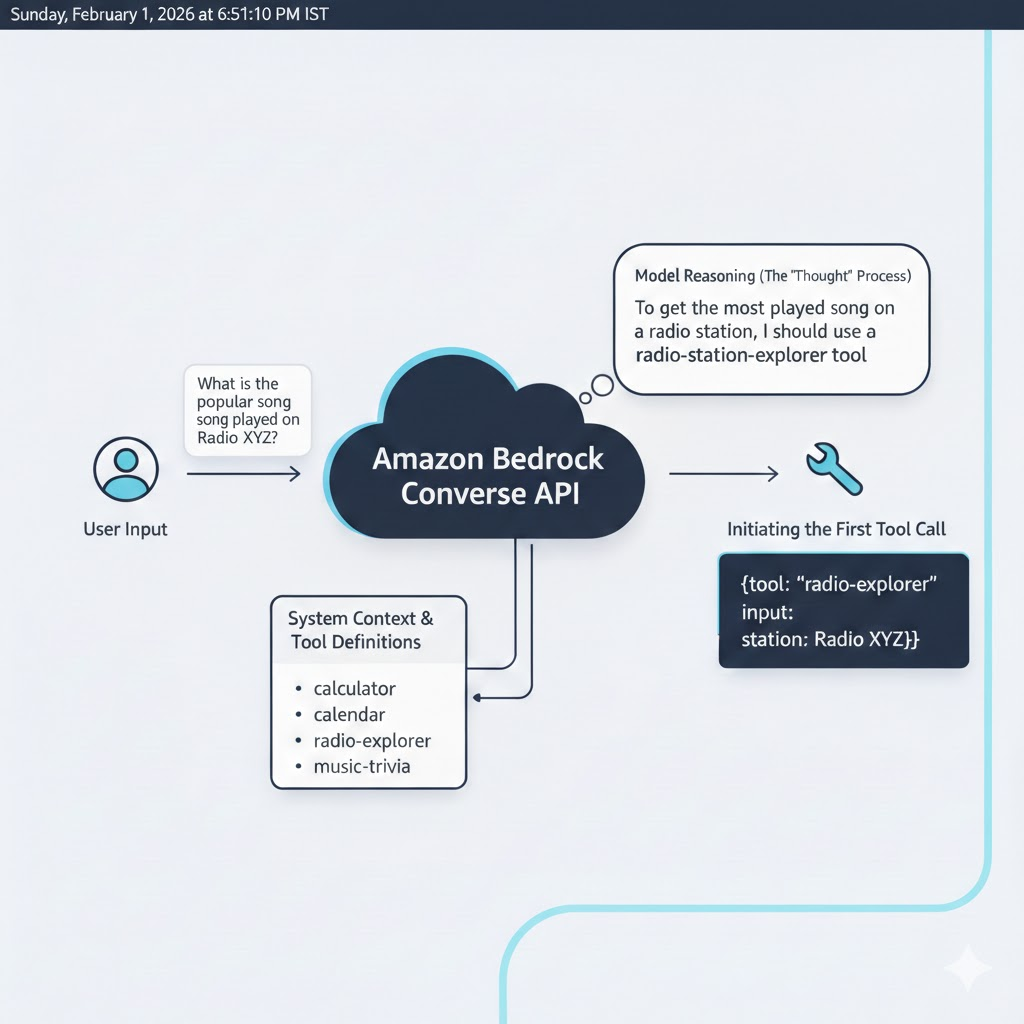
It wasn't until May 30, 2024, that AWS released the Converse API. This update finally standardized these inputs, allowing developers to treat different models (Claude, Nova, Mistral) as interchangeable components without needing to write separate syntaxes for each of them.
But one major breakthrough was the introduction of "tools". Tools were used to compute some business logic, which at that time was out of scope of the model's capabilities. All you had to do was to define the tool using a JSON schema and pass it along with the user message in the Converse API request.
import { ConverseCommand } from "@aws-sdk/client-bedrock-runtime";
// No more "Prompt hacking". We just define the tool structure.
const weatherTool = {
toolSpec: {
name: "get_weather",
description: "Get the current weather for a specific city",
inputSchema: {
json: {
type: "object",
properties: {
city: { type: "string", description: "The city name (e.g. New York)" }
},
required: ["city"]
}
}
}
};
// We pass the tool directly. Bedrock handles the formatting for Claude/Llama/Nova.
const response = await client.send(
new ConverseCommand({
modelId: "anthropic.claude-3-haiku-20240307-v1:0", // Easy to swap!
messages: [
{ role: "user", content: [{ text: "Is it raining in London?" }] }
],
toolConfig: {
tools: [weatherTool]
}
})
);
When a request is sent to the Converse API, the model determines whether a tool is required to generate the next response. If so, it returns a tool_use block describing the tool and its inputs. Your application must detect this block, execute the corresponding function, append the tool's output to the conversation history, and call the Converse API again. The model then uses the tool result to continue reasoning and produce a final response.
The agent tool architecture was quickly gaining popularity, bridging out the feeling of your LLM not having the context it needs to be a true partner to your workflow. Converse fixed interoperability and made tools first-class—but orchestration was still manual, state was still external, and production-grade agents still felt… handcrafted.
While tools were powerful, the developer experience still felt unnatural, writing verbose JSON schemas to describe every function you already understood as code. At the same time, external ecosystems like MCP were proving that tool invocation didn't need to be this verbose or rigid—a signal that another shift was coming
We had models. We had tools. We even had standardized APIs.
And yet, building an agent still felt like assembling a machine by hand—wiring memory, state, and orchestration outside the very system that was supposed to reason for us.
The industry had solved intelligence. It hadn't solved agency.
And how it did we'll explore in Part 2!