ChatGPT
ChatGPT  Perplexity
Perplexity  Gemini
Gemini  Claude AI
Claude AI BigQuery?
BigQuery is a serverless, highly scalable, cost-effective, petabyte-scale enterprise data warehouse solution offered by Google Cloud. It enables you to analyse and query large datasets, without the need for infrastructure management.
Why BigQuery?
Serverless: We don't need to manage any infrastructure; Google handles all the backend operations, such as provisioning, scaling, and managing servers. This allows us to focus on analyzing your data without worrying about the underlying infrastructure.
Standard SQL: We can use familiar SQL syntax to query our data, making it easier for users with SQL experience. Additionally, BigQuery also supports advanced features like window functions, JSON functions, and more, enabling powerful and flexible querying capabilities.
Streaming Data: BigQuery supports streaming data ingestion, enabling you to continuously insert real-time data into your tables for immediate analysis. This feature is particularly useful for applications such as real-time analytics, monitoring, hub and alerting systems.
User-Defined Functions (UDFs): BigQuery allows you to define custom functions in SQL or JavaScript, enabling complex data transformations and calculations directly within your SQL queries.
Scheduled Queries: You can automate repetitive tasks. This feature is ideal for tasks, such as generating daily or weekly reports, updating summary tables, or performing routine data cleaning operations.
Granular Access Control: BigQuery offers fine-grained access control, allowing you to control access at column and row levels, ensuring data security and compliance.
External & Internal Tables: BigQuery supports external tables - allowing you to query data stored in external sources like Cloud Storage, Bigtable, and internal tables - which are stored directly in BigQuery. External tables are useful for integrating BigQuery with other data sources, allowing you to analyze data across multiple systems without the need to move or copy data. Internal tables, on the other hand, are ideal for high performance and scalability for large datasets.
BI Engine: BigQuery BI Engine provides an in-memory analysis service for dashboarding and reporting in BI tools like Data Studio and Looker, delivering sub-second query response times. It does this by caching query results and pre-aggregating data, enabling faster query execution times and reducing the cost of running BI queries.
Machine Learning: BigQuery ML enables you to build and deploy machine learning models directly within BigQuery using SQL syntax, simplifying the process of integrating machine learning into your data analysis workflows.
BigQuery Omni: BigQuery Omni expands BigQuery's analytics reach to data stored in Azure and AWS, enabling cross-platform analysis without data duplication and egress cost. It does this by deploying the BigQuery query engine directly within AWS and Azure regions.
Let's look at BigQuery console..
Prerequisites
- GCP account
- Enable BigQuery API
- Basic SQL Knowledge
- Basic understanding of Data Warehouse
Getting Started
Create Dataset:
A dataset exists within a project. Datasets are top-level containers that are used to organize and control access to your tables and views. A table or view must belong to a dataset, so you must create at least one dataset before loading data into BigQuery.
- Click on ⋮ next to the project name > select Create data set
- Give the data set an ID and click on CREATE DATA SET.
Loading Data
There are multiple ways to load your data on BigQuery, through batch loading (uploading files), streaming (real-time data ingestion), transfer services (automated data movement from SaaS apps), Dataflow (processing and loading data), APIs (programmatic data loading), and third-party ETL tools (integration for data loading). Each method has its strengths depending on data volume, latency needs, and existing infrastructure. In our setup, we will upload the data from the local computer in a CSV file.
Note: Dataset used in this demo can be found here
- Click on ⋮ next to the Dataset name > select Create Table
- Fill in the details:
- Source > Create a table from: Upload
- Source > Select the file by clicking on browse
- Destination > Table: California House Prices
- Schema > Check the Auto-detect box (✅)
- Click on Create Table
- We can view and edit table schema. Also, we can add data quality checks if needed.
Querying Data
QUERY: Click on the + icon and open the query editor. Paste the following query
SELECT * FROM `<project-name>.<dataset-name>.California House Prices`;
QUERY EDITOR OVERVIEW:
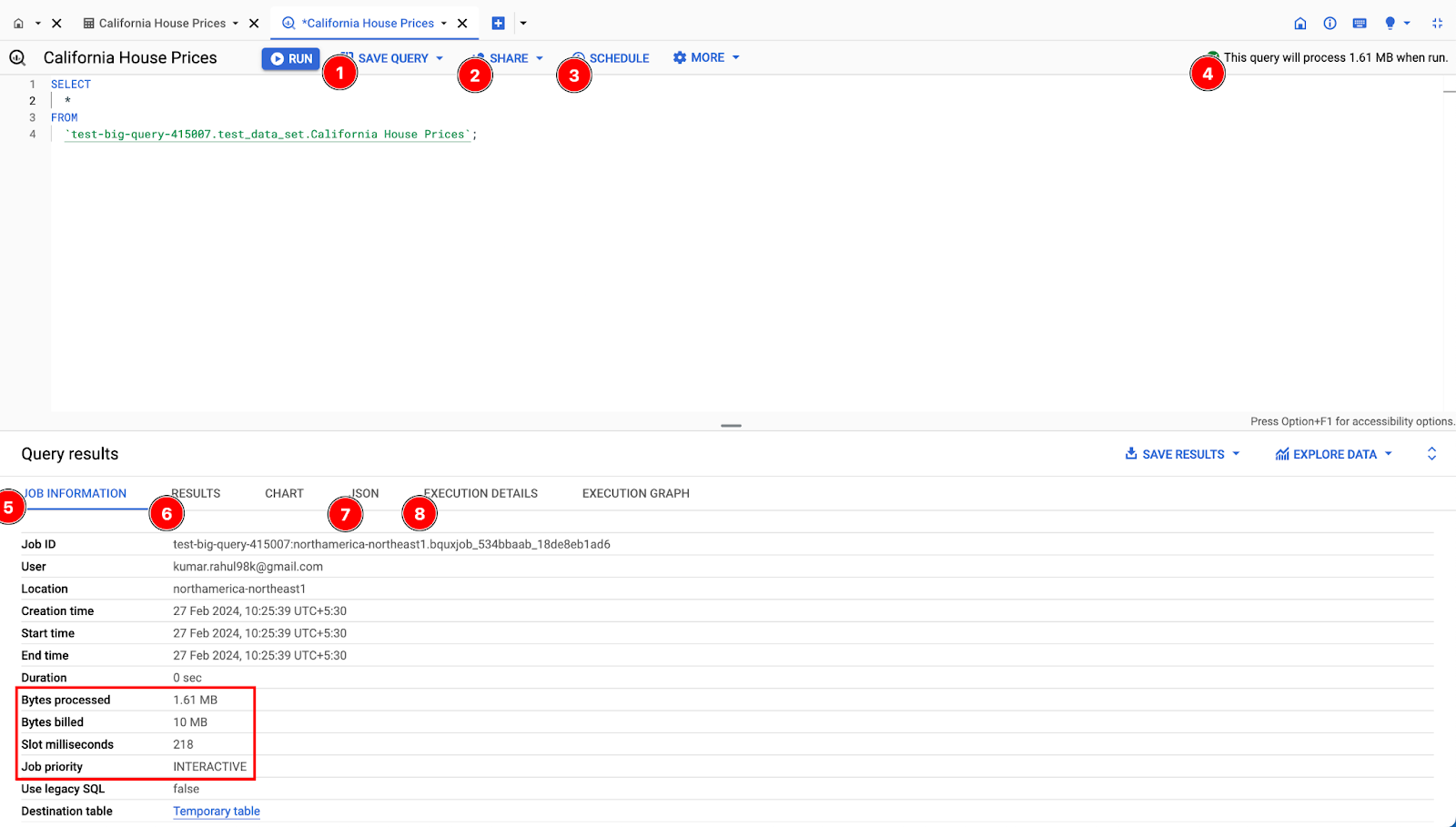
Save Query: Save your query to reuse in the future.
Share: Set the query visibility to personal, project, or public level. Shared query only shares the query text and to run the query one needs to have access to the tables.
Schedule: Schedule your query by setting a start date, end date, and frequency. We can also store the results of these queries in another table and also set up failure notifications.
Query Scan Data: This will show how much data will the query scan when you run it. This is very important as it helps us avoid running expensive queries.
Job Information: Access detailed information about the query job, including its status, start time, and duration.
Result: View and download the query result, which can be stored as a new table or exported to a file in several formats like CSV, JSON, etc.
JSON: View the query result in JSON format, which can be useful for integrating with other systems or applications.
Execution Details: View detailed information about the query execution, such as the amount of data processed and the resources used.
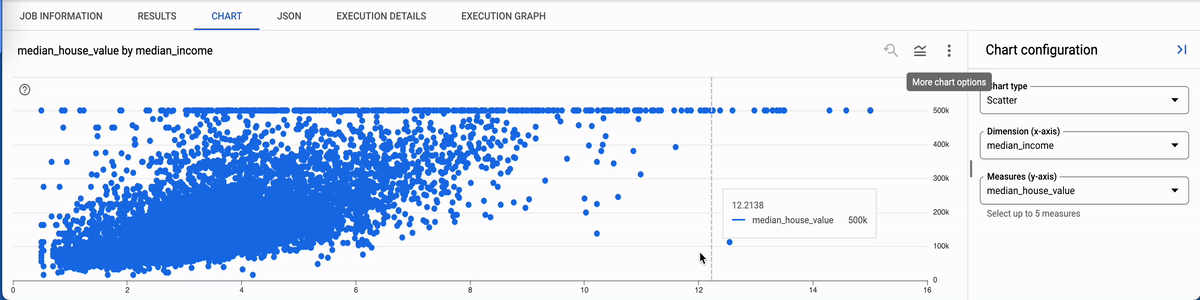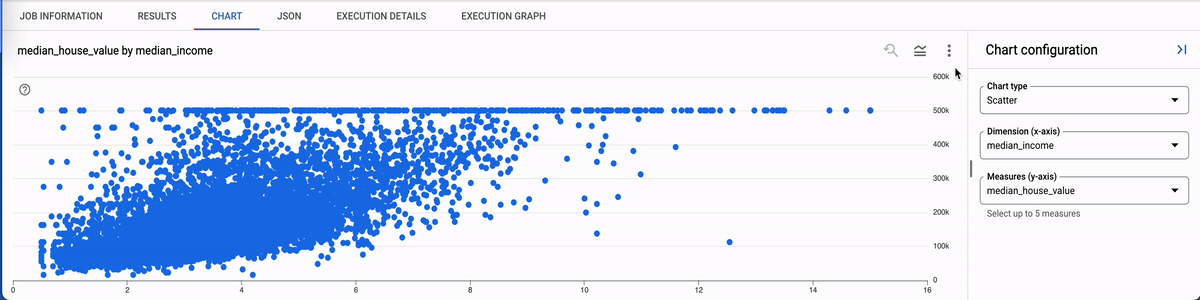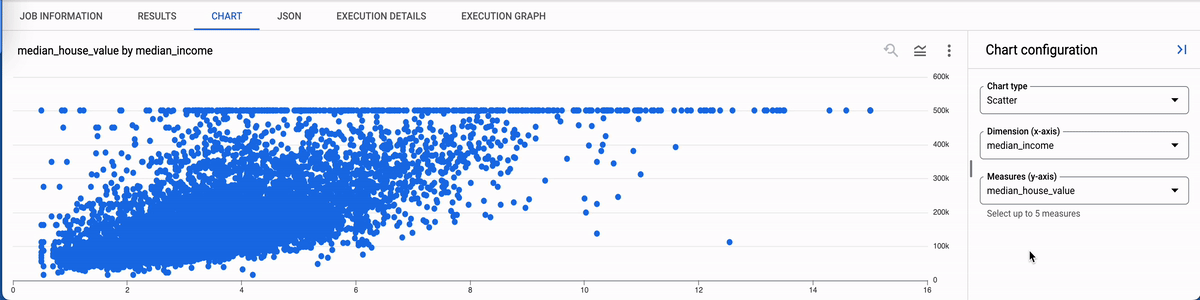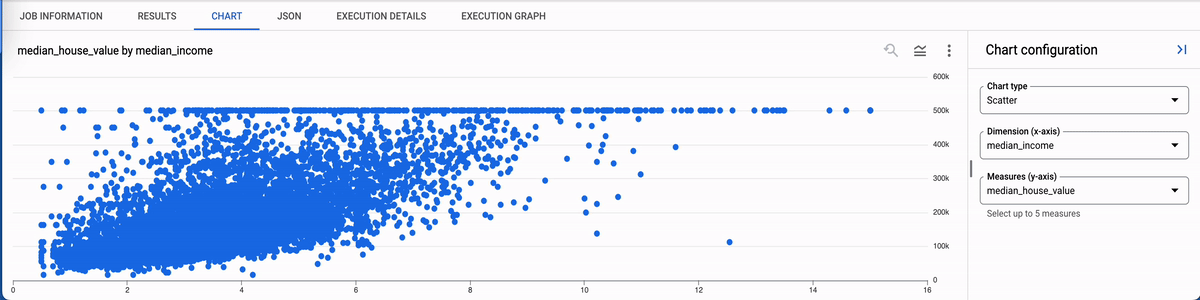
CHARTS: The BigQuery Editor Console provides a visual interface for querying and analyzing data, including the ability to generate various types of charts to represent your data visually. We can use this to quickly generate charts and use them in the presentation. Example: Scatter plot showing how income and house value are related in California.
Note: For beginners, BigQuery's public datasets offer a valuable learning resource. They provide access to real-world data sets, which can be used to practice SQL queries, data analysis, and visualization techniques without the need to set up and manage data sources.
Exporting Data
BigQuery offers several options for exporting data:
- Exporting to Cloud Storage: You can export query results, tables, or entire datasets to Cloud Storage in various formats like CSV, JSON, Avro, etc.
- Exporting to Bigtable: Export BigQuery data to Bigtable for further analysis or integration with other Google Cloud services.
- Exporting to Google Sheets: Export query results directly to Google Sheets for easy sharing and collaboration.
- Exporting via Dataflow: Use Dataflow to export data from BigQuery for complex data processing or transformation tasks.
We can also use the bq CLI tool, the BigQuery API, or client libraries for various programming languages like Python, Java, and Node.js to programmatically run SQL queries.
Optimising BQ Performance
- Partitioning & clustering: Partitioning and clustering are data organization techniques in BigQuery that enhance query performance and cost efficiency. Partitioning divides a table into segments based on a column, improving query speed and reducing costs. Clustering sorts data within partitions based on user-defined columns, further optimizing queries. Combining both techniques can maximize performance: partition first, then cluster within partitions based on columns used in aggregations or joins.
Example: Partitioned and clustered table.
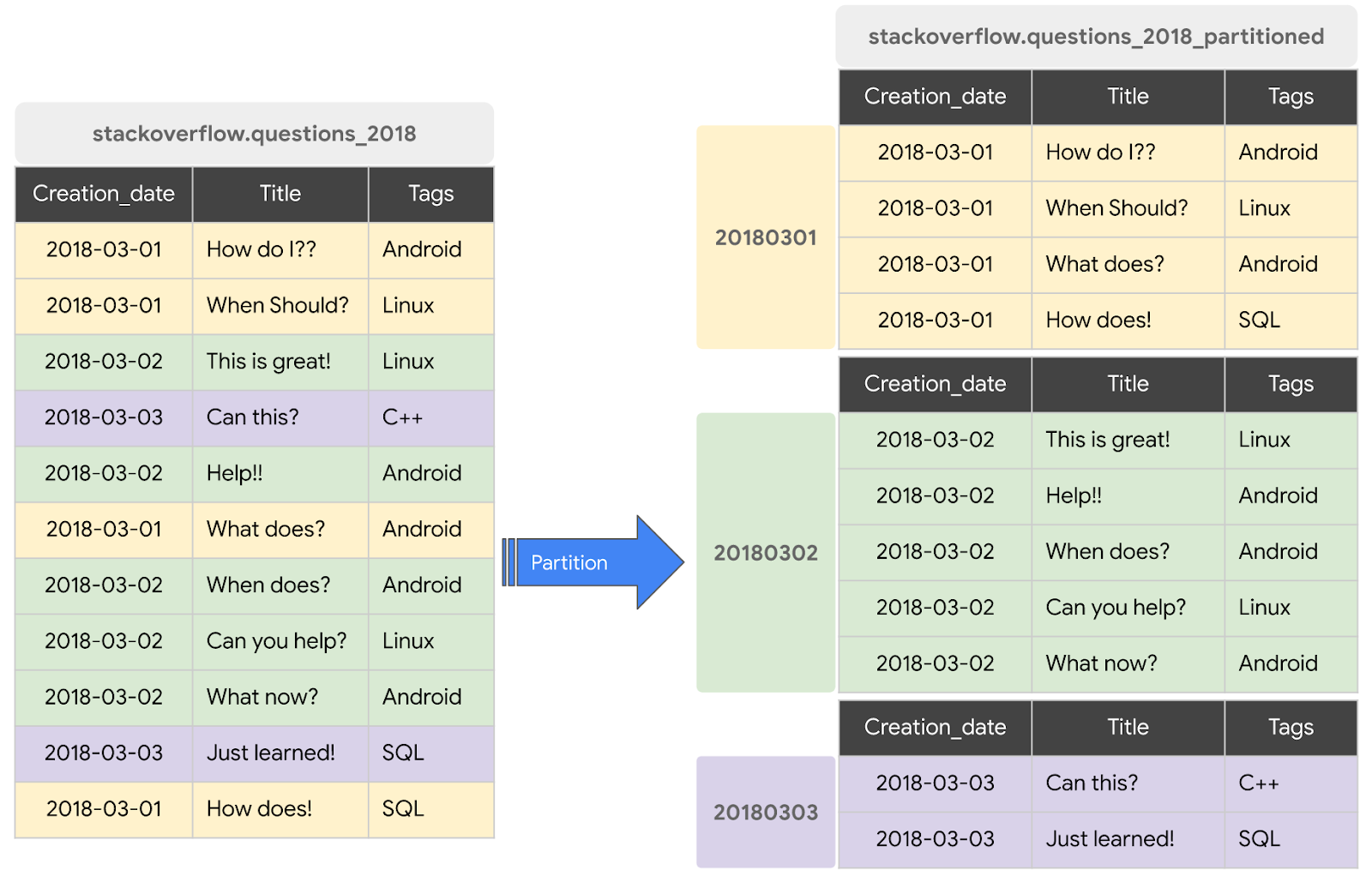
Materialized views: Materialized views in BigQuery are virtual tables that store the results of a query, enabling faster data access and reducing query costs. They are updated either on a schedule or manually, ensuring data freshness. Ideal for dashboards, reports, and pre-aggregating data for analysis. However, they are not suitable for real-time data or large data volumes, and the storage costs should be considered.
Optimize query: Employ approximate aggregation functions, limiting data scanned, avoiding cross joins, utilizing BigQuery's caching, optimizing data types, and monitoring query performance.
Pricing
BigQuery pricing is based on the amount of data processed and stored. It offers 3 pricing options:
On-Demand Pricing: You pay for the data processed by your queries. This is suitable for infrequent or unpredictable workloads.
Flat-Rate Pricing: A fixed monthly price for a certain amount of data processed and stored. This is ideal for predictable workloads.
Slot-Based Pricing: A fixed monthly price for a certain number of query slots. Each slot represents the capacity to run one query at a time. This is suitable for workloads with variable demand.
Additionally, there are costs associated with:
- Data Storage: Charged for the amount of data stored in BigQuery.
- Data Transfer: There are costs for data transferred out of BigQuery to other Google Cloud services or to the Internet.
BigQuery also offers a generous free tier, which includes a monthly allowance of data processed and stored, making it accessible for small-scale projects or testing. Here is blog that talks about BQ pricing in detail: https://medium.com/@akhilasaineni7/understanding-google-bigquerys-storage-and-analysis-pricing-d2bcbf6bb749 \
Note: Queries that return an error or are loaded from cache are not charged.
Pro-tips:
Multi-region datasets: A multi-region is a large geographic area, such as the United States, that contains two or more regions. Multi-region locations provide larger quotas than single regions.
Table Expiry: It allows for the automatic deletion of old or unnecessary data, reducing storage costs, facilitating better data lifecycle management, improving query performance, simplifying data retention policy enforcement
Upload file size limit: When using the Google Cloud console, files loaded from a local data source must be under 100 MB. we need to load larger files from Cloud Storage.
Rename Tables: Tables cannot be renamed, we can do this by copying the table to a new table and then removing the original.
Enable/disable caching for queries: You can control caching behaviour for queries in BigQuery, allowing you to enable or disable caching as needed.
Cached Queries: There is no execution graph for cached queries.
Sampling: BigQuery allows you to perform table sampling which involves querying a random subset of data from a large table. Example query:
SELECT * FROM your_table WHERE RAND() < 0.1;
Geography Function: GoogleSQL for BigQuery supports geography functions.
Complex queries: BigQuery is tailored for handling advanced queries. blog