ChatGPT
ChatGPT  Perplexity
Perplexity  Gemini
Gemini  Claude AI
Claude AI During Super Bowl LIX, I watched something remarkable unfold.
FOX pulled off one of the most impressive real-time data operations in live broadcast history. Their Media Collection and Viewership Beaconing Service (MCVBS), powered by Momento, Amazon Athena, and Amazon S3, delivered second-by-second visibility into the viewer experience, handling over 25 billion beacons from 15.5 million concurrent devices without a single delivery failure.
What stood out to me wasn’t just the infrastructure. It was the clarity of design.
With real-time metrics surfacing up to a minute faster than traditional dashboards, the result was not just a flawless broadcast. For me, it was a classic demonstration of how serverless architecture and edge-to-cloud telemetry can reshape the future of media intelligence at massive scale.
Breaking Down the Orchestration Layers
What FOX achieved during Super Bowl LIX was orchestration at its sharpest.
As I dug into their architecture that powered this broadcast milestone was purpose-built to adapt under extreme pressure. Years of planning culminated in a system that anticipated them, absorbed them, and routed around them in real time.
The orchestration layer followed a three-pronged strategy:
Massively Scale Up - Resilient by Default - Disaster Recovery Switches
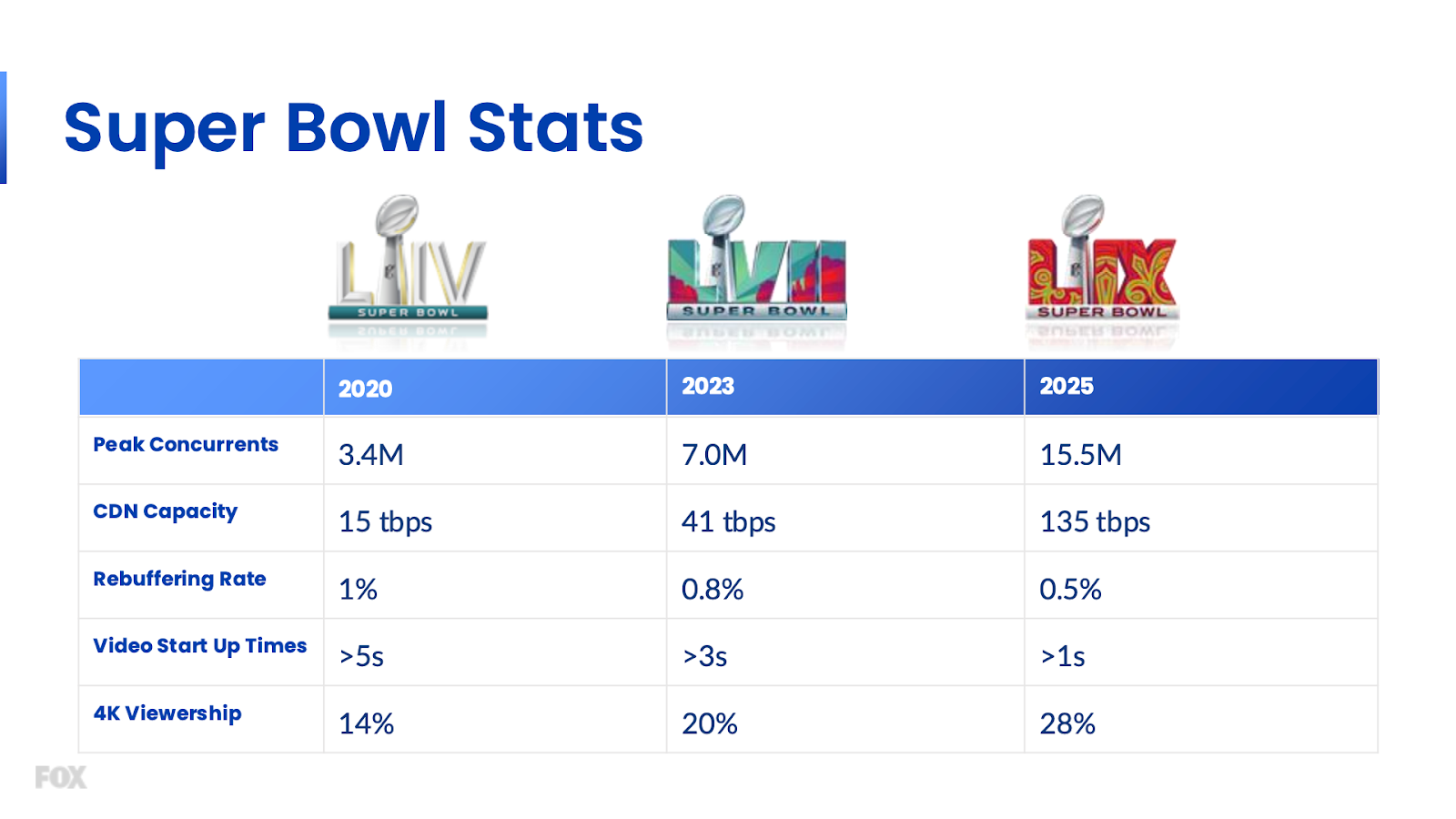
Caption: Super Bowl LIX Streaming Insights
This is what modern readiness looks like.
1. Smart Multi-CDN Orchestration
- Traffic Distribution: FOX implemented a smart, multi-CDN orchestration layer to split and steer 135 Tbps of traffic in real-time across Akamai, Fastly, Qwilt, and Amazon CloudFront, ensuring that no single CDN was overloaded and that regional performance was optimized.
- Fine-Grained Control: The orchestration layer provided granular control over the percentage of traffic sent to each CDN.
- Health-Based Steering: If a CDN exhibited signs of congestion or failure, traffic was instantly rerouted to healthier CDNs with no user impact.
- Redundancy & Failover: The architecture included both small object (e.g., manifest files) and large object (e.g., video segments) redundancy.
2. Disaster Recovery & Resilience
- Disaster Recovery Mode: FOX engineered a remote configuration allowing Tubi (the primary streaming platform) to fall back to a minimal “Super Bowl only” mode in the event of a failure in the stack.
- Load Testing & Chaos Engineering: More than ten full-scale dress rehearsals and chaos tests were conducted in production to handle unexpected load spikes or CDN outages.
3. Playback Telemetry & Analytics Integration
- Real-Time Instrumentation: FOX’s orchestration layer was tightly integrated with playback telemetry, providing second-by-second visibility into viewer experience, buffer status, and CDN performance for millions of concurrent sessions.
- Analytics Feedback Loop: Data from Momento and Hydrolix log ingestion enabled instant feedback to the orchestration layer.
4. Operational Excellence
- API Optimization: All critical APIs in the streaming path were scaled to a minimum SLA of 200,000 requests per second to ensure resilience under peak demand.
Why Your Backend Should Work Like This
You don’t need to stream the Super Bowl to feel the pressure of concurrency. I’ve seen healthcare portals buckle under enrollment surges, e-commerce platforms slow to a crawl during flash sales, and fintech systems scramble to process trades in real time. These are streaming problems in disguise.
The lesson here is simple: architect for bursts, not averages. What modern platforms need is situational awareness.
- Systems today should ingest telemetry as a first-class citizen.
- Treat client-side signals as more than logs.
- Designing for observability, fallbacks, and edge-distributed logic.
If a search query volume spikes in a specific region, the system should detect, absorb, and rebalance traffic.
If transactions fail at a higher rate post-deployment, the system should isolate that condition and trigger rollback protocols.
If 50,000 users all hit “Buy Now” at 9:59 am, your backend shouldn’t guess what to do, it should be primed.
The goal isn’t to mimic media infrastructure, but to build systems that are observant, elastic, and inherently ready for volatility.
Trigger-Based Scaling: A Blueprint for Modernization
Modernization isn’t a sprint toward serverless, it’s a shift in how your systems respond to the world around them. For me, the real shift lies in trigger-based scaling: architectures that activate in response to user behavior, data signals, and operational events, rather than idle provisioning or guesswork.
“Scaling used to mean planning for peaks. Now it means listening for signals, and reacting fast enough to matter.”
Here’s how that unfolds in practice:
1. Critical paths are refactored into discrete, stateless, triggerable units, Lambda functions, Step Functions, and event bridges become the connective tissue. These units don’t run unless triggered, and when they do, they scale horizontally and independently, without orchestration overhead.
2. System design biases toward simplification. Critical path APIs strip retries, and fallback logic is moved outside of the synchronous layer. Decisions that once required synchronous computation are either frontloaded to data preparation or offloaded to edge caching.
3. Observability and chaos are embraced early. The system is engineered not just to scale, but to prove it, under load, under failure, and in production.
4. Ops shifts from reactive firefighting to proactive rehearsal. Incident response becomes muscle memory because scaling becomes predictable, and disaster scenarios are benchmarked.
Media and entertainment is entering an era where infrastructure must perform with the same precision and tempo as the content it delivers. At AntStack, we believe in anticipating the new reality. If you’re ready to move from static systems to infrastructure that responds, serverless-led infrastructure is the path forward.
Resources: