ChatGPT
ChatGPT  Perplexity
Perplexity  Gemini
Gemini  Claude AI
Claude AI Since the release of ChatGPT last year, Natural Language Processing(NLP) has taken a massive leap forward. With its ability to generate human-like text, developers worldwide have been experimenting and innovating with it to build a plethora of applications. It has also been used extensively by non developers from content creators to customer service representatives to improve their workflows and provide better experiences for their customers.
In this blog, we will explore how to build a Serverless QA Chatbot on a website using OpenAI's Embeddings and GPT-3.5 model, create a Vector Database with Pinecone to store the embeddings, and deploy the application on AWS Lambda, providing a powerful tool for the website visitors to get the information they need quickly and efficiently.
Getting Started
Here are some prerequisites to build the Serverless QA Chatbot:
- OpenAI account with an API Key
- Pinecone account with an API Key
- Familiarity with Natural Language Processing (NLP) concepts and techniques
- AWS account and basic knowledge of serverless architecture
Let's get started.
Building a QA System
We are going to follow OpenAI's tutorial or this notebook to build the QA system.
Here are the steps that we follow in the above tutorial:
- Build a web crawler to scrape all the text data from our website
- All the text data scraped are dumped into a CSV file so that they can be loaded as a DataFrame using Pandas.
- The text data in the CSV file is converted to Embeddings with OpenAI's Ada 002 model.
- A question and answer system is created using the embeddings, which takes a user's question, creates an embedding of it, and compares it with the existing embeddings to retrieve the most relevant text from the scraped website.
- The GPT-3.5 model generates a natural-sounding answer based on the retrieved text.
Handling the Rate Limit Error
The common issue faced when you're building any OpenAI powered application with a free account is the Rate Limit error. In the OpenAI's tutorial, we come across that error when we try to create embeddings for our text data.
To handle the Rate Limit error from OpenAI's API, we are going to use the Tenacity library. This library provides an easy way to add exponential backoff with jitter and retry so that the function call will eventually succeed without overloading the API server.
import openai
from tenacity import (
retry,
stop_after_attempt,
wait_random_exponential,
) # for exponential backoff
@retry(wait=wait_random_exponential(min=1, max=55), stop=stop_after_attempt(600))
def completion_with_backoff(**kwargs):
return openai.Embedding.create(**kwargs)['data'][0]['embedding']
df['embeddings'] = df.text.apply(lambda x: completion_with_backoff(input=x, engine='text-embedding-ada-002'))
df.to_csv('processed/embeddings.csv')
df.head()
The completion_with_backoff() function takes input text and engine as input arguments and uses the OpenAI API to create an embedding of the input text using the specified engine. The function is decorated with @retry and will retry the function call if it encounters a rate limit error. The wait_random_exponential() method provides exponential backoff with jitter to wait before retrying the function call. Finally, the generated embeddings are stored in the embeddings column of the DataFrame and are saved to a CSV file.
Uploading the data to Pinecone Vector Database
Now that we have generated embeddings for our website's text data and put it in a CSV file, we need a way to store and retrieve these embeddings efficiently. In this section, we will explore how to use Pinecone, a managed vector database, to store our embeddings and build a fast and scalable search index. We will also learn how to query the index to retrieve the most relevant embeddings for a given search query.
Why use Vector Database?
You might be wondering why we aren't querying the CSV file to retrieve our embeddings. Even though we can do that for smaller datasets and research level applications, using a Vector Database is the right approach for a production level application.
As mentioned above, a Vector Database like Pinecone allows for fast and efficient similarity search using embeddings. Compared to searching through a CSV file, Vector Databases enables us to quickly retrieve embeddings and perform similarity searches using cosine similarity. Pinecone works by creating an index of embeddings that are optimized for similarity search. When a query is made, Pinecone searches the index for the most similar embeddings and returns the corresponding data points. By using Pinecone, we can efficiently store and retrieve our embeddings, allowing for faster and more accurate similarity search.
To get started, you need a Pinecone account. After creating an account, head to the API Keys section and copy both API Key Value and Environment Name to your local environment file.
Follow these steps to create a Pinecone Index and upload your data:
- After importing the library and loading the env variables, create the index:
import os
import pinecone
pinecone_key = os.getenv("PINECONE_KEY")
pinecone_env = os.getenv("PINECONE_ENV")
pinecone.init(
api_key=pinecone_key,
environment=pinecone_env # find next to API key in console
)
pinecone.create_index('embeddings', dimension=1536, metric='cosine')
index = pinecone.Index('embeddings')
- Load your CSV file and upload the data in batches:
import pandas
df = pd.read_csv("embeddings.csv", index_col=0)
df['embeddings'] = df['embeddings'].apply(eval).apply(np.array)
batch_size = 32 # process everything in batches of 32
for i in range(0, len(df), batch_size):
# set end position of batch
i_end = min(i+batch_size, len(df))
# get batch of lines and IDs
lines_batch = df['text'][i: i+batch_size]
n_tokens_batch = df['n_tokens'][i: i+batch_size]
embeddings_batch = df['embeddings'][i: i+batch_size]
ids_batch = [str(n) for n in range(i, i_end)]
embeddings = [e.tolist() for e in embeddings_batch]
metadata = [{'text': text, 'n_tokens': n_tokens} for text, n_tokens in zip(lines_batch, n_tokens_batch)]
# upsert batch
to_upsert = zip(ids_batch, embeddings, metadata)
index.upsert(list(to_upsert))
This uploads all the data to Pinecone. Now we can query the index and get the top X results:
import openai
query = "What is Serverless?"
xq = openai.Embedding.create(input=query, engine='text-embedding-ada-002')['data'][0]['embedding']
res = index.query([xq], top_k=5, include_metadata=True)
for match in res['matches']:
print(f"{match['score']:.2f}: {match['metadata']['text']}")
top_k set to 5 indicates that the five nearest embeddings are returned to the query. Note that we are also setting include_metadata to True so that even the text for the corresponding embedddings are returned.
This is the result for the above query:
0.88: k.com blog unfolding serverless what is serverless and why it matters. Unfolding Serverless: What is Serverless and Why it Matters What makes us uniqueResourcesBlogCase StudiesEventsAntverseBuild With UsWhat makes us uniqueCase StudiesBlogEventsAntverseBuild With Usconnect@antstack.com May 14, 2021 10 min read Unfolding Serverless: What is Serverless and Why it Matters Deen E David serverless Letâs dial back the clock before we jump into the whole serverless era, which would include Serverless Computing, Database, Storage, an organisation so much more. Back in 1989, when Tim Berners-Lee, a British scientist, invented the World Wide Web while working with CERN, it had one sole purpose - to meet the demand for automated information-sharing between scientists and institutes the globe. Tim wrote the first proposal for the World Wide Web in March 1989 and a second in the following year. And with the assistance of Robert Cailliau, this was formalised as a management proposal in November 1990. By the end of 1990, Tim had the first server and browser up and running at CERN. He developed the code for his Web server on a NeXT computer. To prevent it from being accidentally turned off, the NeXT computer had a hand-written label in red ink, Source: AppStorey Rest is history. Developers were on the idea of being limited because of the limitations of a physical server. Instead of trying to be more efficient with creating and designing code, they had to bottleneck themselves a sizable amount of time caring about the server infrastructure. We got presented with a diverse set of assets, maintenance on a loop. There was no getting around it. Say it updating servers, repairing hardware, reliable connectivity, over and under-provisioning with the usage and burning a hole in your pocket and so on. And because of all these reasons, you end up spending the majority or handful of your time maintaining servers and looking after them. In comes the cloud providers with a solution, Introducing Serverless Itâs a cloud-based service where the cloud providers - AWS, Azure, Google Cloud Platform and others will manage the servers for you. They dynamically allot the compute and storage resources as needed to execute a particular line of code. So, naturally, servers are still part of the circle.
0.88: k.com blog serverless is not just aws lambda. Serverless is not just AWS Lambda What makes us uniqueResourcesBlogCase StudiesEventsAntverseBuild With UsWhat makes us uniqueCase StudiesBlogEventsAntverseBuild With Usconnect@antstack.com Jul 26, 2021 11 min read Serverless is not just AWS Lambda Deen E David aws serverless âServerless is the fastest way to build modern applicationsâ - Adrian Cockcroft, VP Cloud Architecture Strategy, AWS. The path for an organisation for a transformation could look different for different organisations. And thereâs nothing that we have certain for everyone. You will be faced with two options: to build that fantastic new feature or system in a serverfull way or serverless. The serverfull way looks no trouble and safe, and the serverless way looks more handful for your organisation. The serverfull way roads seem like more travelled than the serverless way which is less travelled. In reality, both the roads are equally travelled and lead to the same destination. All roads lead to Serverless because one has to create value for the organisation and customer faster. Serverless means:1. Never having to patch another OS.2. Never being paged when a rack goes down.3. Never needing to rollout software on a hundred nodes.4. Never paying for idle infrastructure.5. Never losing business because you can't scale. pic.twitter.com/pUrby2odaWâ Rick Houlihan (@houlihan_rick) October 3, 2020 Serverless removes the undifferentiated heavy lifting: No infrastructure provisioning and no management. Pay for the value Automatic scaling Highly available and secure Serverless is there for you, at every layer Compute and Access AWS Lambda: AWS Lambda is an event-driven, serverless computing platform provided by Amazon as a part of Amazon Web Services. With Lambda, you can run code for virtually any type of application or backend service - all with zero administration. Helping you to focus on your core product and business logic instead of managing operating system (OS) access control, OS patching, right-sizing, scaling, etc.
0.88: k.com blog the future of cloud serverless. Serverless: The Future Of Cloud What makes us uniqueResourcesBlogCase StudiesEventsAntverseBuild With UsWhat makes us uniqueCase StudiesBlogEventsAntverseBuild With Usconnect@antstack.com Feb 17, 2023 4 min read Serverless: The Future Of Cloud Editorial Team serverless Serverless is a cloud computing model allowing users to run their applications without managing a server. Serverless doesnât mean that the server is not present but is managed separately from the applications. A cloud provider handles the serverless architecture. App developers must package their code and deploy it through containers that package software with elements required to run in any environment. Serverless computing has been around for less than a decade. This emerging technology is gaining popularity in cloud computing, allowing developers much more flexibility than traditional cloud options. In this innovative technology, an external source manages the serverâs infrastructure. The growth of serverless computing has been swift. It has become a vital component of the next-generation cloud infrastructure due to the ability to code without worrying about the crucial work of all necessary hardware and software. The idea behind serverless computing is that coding is done in any language or framework and then run on a platform that handles scaling availability. You may pay for only the resources consumed during execution. Traditionally, the payments also went for idle time or unused capacity, but with serverless, all such extra costs are negated. Advantages Of Serverless Architecture Low cost No server management is necessary Better scalability Improved flexibility Evolution Of App Monitoring All apps require monitoring, and serverless monitoring has unique advantages that more and more developers are utilising as a service. For instance, applications can be scaled instantaneously while serving as many users as required. This cut costs drastically as one needs to pay for what one needs. Startups are taking advantage of this ability because they can try to lift their business with a fraction of the traditional budget. There are numerous tools available for serverless monitoring. When monitoring serverless, the focus should be on the entire function. What Should Be Monitored? Cold Starts Errors Success Request Ratio Latency Cost Infrastructure As Code Earlier, computer infrastructure could only be managed through manual intervention. Servers had to be mounted on racks, and the operating systems had to be installed. This was an issue when infrastructure changes were frequent.
0.88: Still, the cloud providersâ catering and life support was handled entirely and were not exposed as physical or virtual machines to the developer running the code. As far as the user is concerned, a serverless back-end would scale and load balance automatically as the application load fluctuates (high or low) while keeping the application up and running seamlessly. That would ultimately mean that there is a promise made by reducing the development cycles for a business or organization at any levels with a major hold of how operational costs can be controlled. Such freedom allows developers to build applications without having the trouble of managing or looking after an infrastructure without: Clinching to functionality Prolonging server uptime They ultimately allowed the dev team and assets to keep their hands all in driving the transformation in this modern digital era. Gone are the days when it was known as âcutting-edge techâ. Serverless is being adopted, and itâs getting more mainstream for business which is established already and for those who are just starting out - Serverless is being adopted by devs discovering the ease and cost-effectiveness of adopting serverless computing, especially if you need speeding up and scaling the process. The Core Serverless Components Even though itâs architecture at the very roots, the code is designed to work with FaaS and BaaS from third-party vendors. All these platforms work based on a pay-as-you-use model. Based on the runtime of the use of functions, and charges the customers accordingly. Even though Faas and BaaS takes up the significant chunk, youâll need to be aware of the other components too, Serverless Framework The Serverless Framework is a tool wrapped in a programming framework that can be used to deploy cloud functions and serverless applications to cloud service providers like - AWS, Azure, GCP. Note: There is a substantial difference between frameworks and platforms when it comes to serverless. There are many serverless frameworks out there which you can dig into in the year 2021. Each of them has various features that offer so much in terms of multi-cloud development, supporting multiple languages, open-source, automated deployment, etc. Serverless Database When you are creating or designing an application, one of the vital considerations you need to decide is which database to use for your cloud application. Knowing whatâs required can significantly help you choose the right database service, which can help you get started with using the tech stack of today.
0.87: k.com blog student entrepreneurs and serverless. Students and Serverless - The Uncharted Realm What makes us uniqueResourcesBlogCase StudiesEventsAntverseBuild With UsWhat makes us uniqueCase StudiesBlogEventsAntverseBuild With Usconnect@antstack.com Mar 22, 2021 6 min read Students and Serverless - The Uncharted Realm Sandeep Kumar P entrepreneur serverless Why Serverless? Serverless computing is one of the fastest-growing cloud public services. The advancement of technology from servers to dockers and the elevation in cloud computing inevitably leads to Serverless computing. Serverless architecture is the Tetris of the jigsaw puzzle. Solving the applicationâs problem is easy and quite a lot of fun. Living in a world of instant gratification, why does IT need to be any different? Serverless computing has a low time to market (TTM) and highly scalable. In a serverless architecture, the application infrastructure (servers, networks, etc.) and its management (scaling, updates, etc.) are taken care of by the cloud provider. What Does It Have To Do With Students? Students are highly optimistic, full of life, and have a lot of time. It is one of the best times in their life to start a business. In todayâs world, an MVP (minimum viable product) or at least a prototype of the application is a must to sell your idea to the right people. When it comes to an application, the code and infrastructure are like the two sides of a coin. The code part, to an extent, is covered as part of the college curriculum. The initial infrastructure setup might be overwhelming but, thatâs where serverless architecture rocks. Since serverless architecture abstracts the infrastructure layer, setting up and maintaining infrastructure is simple. So you donât have to spend much time on it and dive directly into coding your business logic. One of the reasons why students give up on their ideas is the cost involved in building and running the application during the ideation/prototype phase. But, what if we could overcome it? The cost of prototyping a simple serverless application is highly economical, and if you include the free tier offers, the total cost is negligible. Application Prototyping Cost ( < $0.5 ) Letâs dive into the cost of building an application on Amazon Web Services (AWS) using serverless services.
The five embeddings are essentially the five nearest vectors to the question that was asked. That is why there is also a score that is returned, indicating the percentage of match.
Deploying the Application with AWS SAM
We are deploying the application with AWS SAM, which allows us to create and manage serverless applications quickly and easily.
Since the libraries and its dependencies exceed the Lambda Layers' limit of 250MB, we will use Elastic Container Repository(ECR) to store the container image, which is later used to deploy the application.
If you want to know about AWS SAM, visit here. If you need instructions to install it, visit here.
We will use SAM's TensorFlow example template. After installing SAM, follow these steps:
- Enter sam init in the terminal.
- Select AWS Quick Start Templates.
- Next, select Machine Learning and choose Python 3.9 runtime.
- Finally select TensorFlow ML Inference API and give a name for the stack.
Follow this if you are having difficulty navigating through SAM.
Open the downloaded repo and modify the requirements.txt file:
openai==0.27.0
pandas
numpy
matplotlib
plotly
scipy
scikit-learn
pinecone-client==2.2.1
Replace the commands in the Dockerfile with the below snippet:
FROM public.ecr.aws/lambda/python:3.9
COPY app.py requirements.txt ./
RUN python3.9 -m pip install -r requirements.txt -t .
CMD ["app.lambda_handler"]
This is the code for app.py:
import boto3
import json
import openai
import pinecone
ssm = boto3.client('ssm')
openai.api_key = ssm.get_parameter(Name='OPENAI_API_KEY', WithDecryption=True)['Parameter']['Value']
pinecone_key = ssm.get_parameter(Name='PINECONE_KEY', WithDecryption=True)['Parameter']['Value']
pinecone_env = ssm.get_parameter(Name='PINECONE_ENV', WithDecryption=True)['Parameter']['Value']
pinecone.init(api_key=pinecone_key, environment=pinecone_env)
index = pinecone.Index('openai')
def create_context(
question,
):
"""
Create a context for a question by finding the most similar context from the pinecone index
"""
max_len=1800
# Get the embeddings for the question
q_embeddings = openai.Embedding.create(input=question, engine='text-embedding-ada-002')['data'][0]['embedding']
# Get the distances from the embeddings
res = index.query([q_embeddings], top_k=5, include_metadata=True)
returns = []
cur_len = 0
for match in res['matches']:
text = match['metadata']['text']
n_tokens = match['metadata']['n_tokens']
# Add the length of the text to the current length
cur_len += n_tokens + 4
# If the context is too long, break
if cur_len > max_len:
break
# Else add it to the text that is being returned
returns.append(text)
# Return the context
return "\n\n###\n\n".join(returns)
def answer_question(
model="gpt-3.5-turbo",
question="What is AntStack?",
debug=False,
max_tokens=150,
stop_sequence=None
):
"""
Answer a question based on the most similar context from pinecone
"""
context = create_context(
question,
)
try:
# Create a completions using the question and context
response = openai.ChatCompletion.create(
temperature=0,
max_tokens=max_tokens,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=stop_sequence,
model=model,
messages = [
{"role": "system", "content": f"You are a chatbot for a Serverless company AntStack and strictly answer the question based on the context below, and if the question can't be answered based on the context, say \"I'm sorry I cannot answer the question, contact connect@antstack.com\"\n\nContext: {context}\n\n---\n\nQuestion: {question}\nAnswer:"},
]
)
return response["choices"][0]["message"]["content"]
except Exception as e:
print(e)
return ""
def lambda_handler(event, context):
body = json.loads(event["body"])
prompt = body["prompt"]
response = answer_question(question=prompt)
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json",
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Headers": "*",
"Access-Control-Allow-Methods": "*",
"Access-Control-Allow-Credentials": True
},
"body": json.dumps({
"response": response
})
}
You might have noticed that in line 6, we are loading something called 'ssm' and getting the secret keys from it. This is AWS Systems Manager. We are storing our keys in 'Parameter Store' and later loading the keys on Lambda.
To upload the keys,
- Go to Systems Manager
- In the navigation panel under Application Management, go to Parameter Store.
- Choose Create Paramater
- Give a name to the key, choose Secure String and under Value, paste your API key string.
Do the same for all the 3 keys. OpenAI's API key can be found here. Pinecone's API Key and Environment can be obtained from https://app.pinecone.io/ under API Keys section.
Now, we will build and deploy the application. Before building the application, make sure Docker is installed and running. To install Docker, visit here.
Make sure Docker is running. Enter:
sam build
The commands entered in the Dockerfile are executed. If the build runs successfully, the below message is shown,
 Now, enter:
Now, enter:
sam deploy --guided
The below is how you should configure:
Configuring SAM deploy
======================
Looking for config file [samconfig.toml] : Found
Reading default arguments : Success
Setting default arguments for 'sam deploy'
=========================================
Stack Name [stack-name]: openai
AWS Region [us-east-1]:
#Shows you resources changes to be deployed and require a 'Y' to initiate deploy
Confirm changes before deploy [Y/n]: y
#SAM needs permission to be able to create roles to connect to the resources in your template
Allow SAM CLI IAM role creation [Y/n]: y
#Preserves the state of previously provisioned resources when an operation fails
Disable rollback [y/N]: n
InferenceFunction may not have authorization defined, Is this okay? [y/N]: y
Save arguments to configuration file [Y/n]: y
SAM configuration file [samconfig.toml]:
SAM configuration environment [default]:
Later, you need to approve the deployment in the terminal. It will look similar to this:
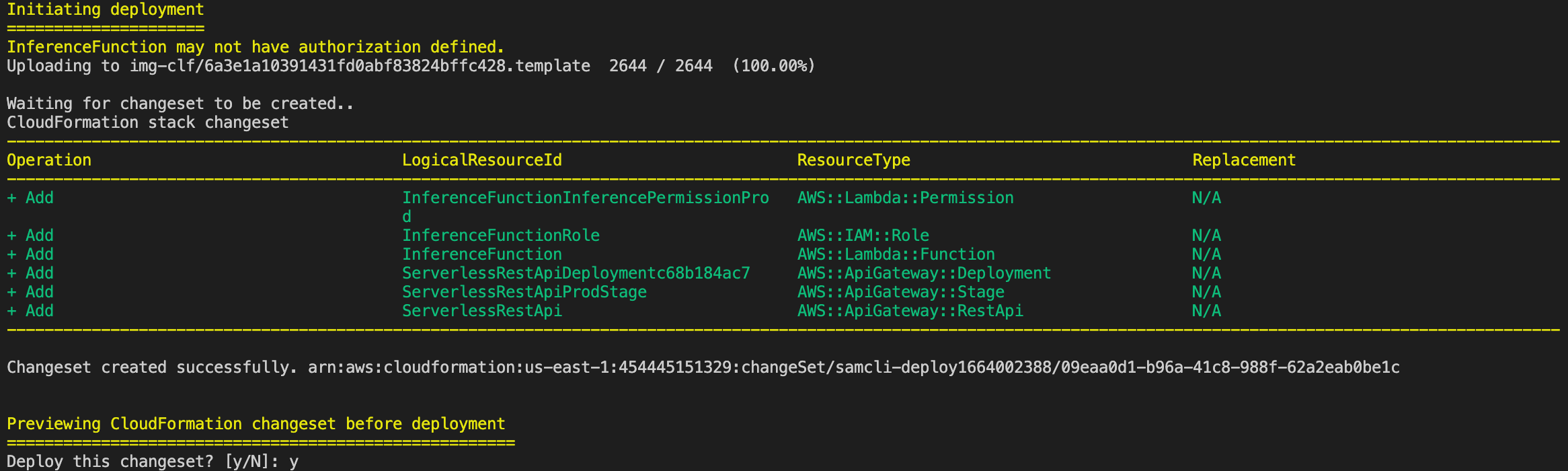 All the resources mentioned in the template.yaml are created and upon successful creation, the API link is shown,
All the resources mentioned in the template.yaml are created and upon successful creation, the API link is shown,
------------------------------------------------------------------------------------------------------------------------------------------------------------
Outputs
------------------------------------------------------------------------------------------------------------------------------------------------------------
Key InferenceApi
Description API Gateway endpoint URL for Prod stage for Inference function
Value https://API-ID.execute-api.REGION.amazonaws.com/STAGENAME/answer
------------------------------------------------------------------------------------------------------------------------------------------------------------
Test the endpoint with Postman:
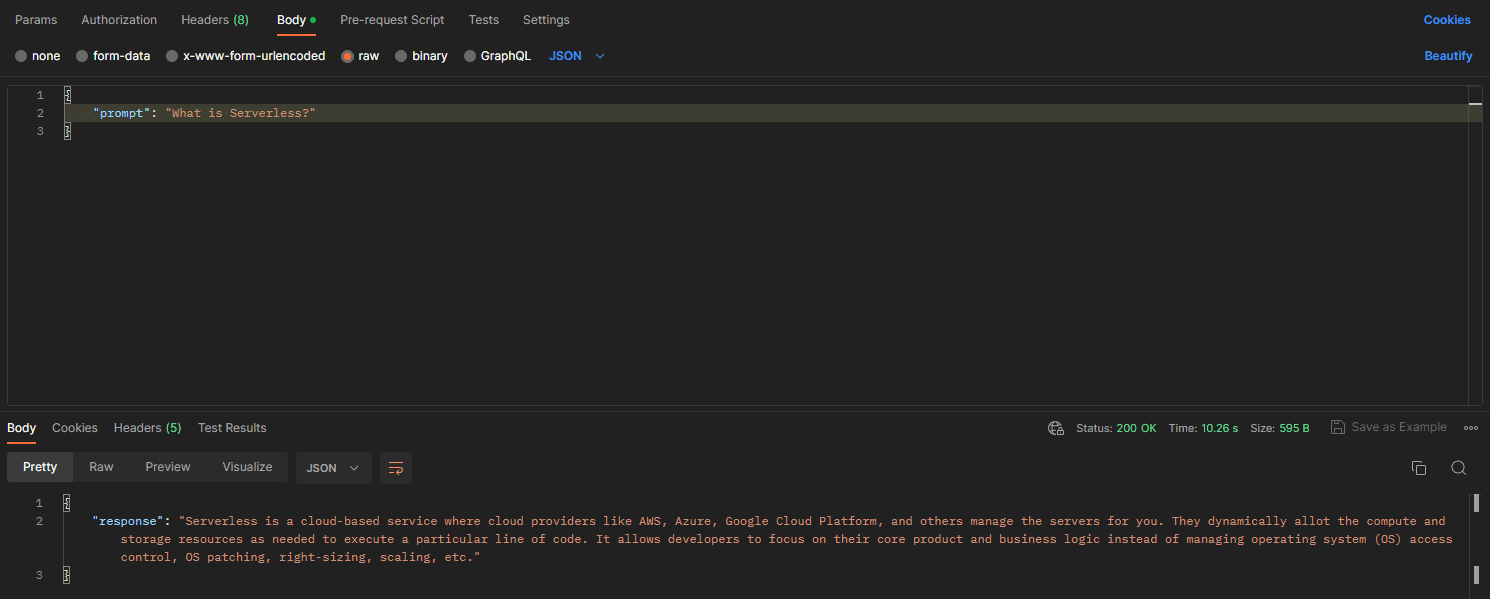
You can build a UI similar to this and have an interactive chatbot for your own application.

CONCLUSION
You've done it! You have successfully built a basic QA System with GPT-3.5, Pinecone and AWS Lambda. The whole process of building a chatbot outlined in this blog can also be followed to build a similar conversational bot for any use case. You can explore Langchain and other similar libraries to expand upon this knowledge. If you have any feedback, reach out to my LinkedIn or Twitter!