

 ChatGPT
ChatGPT  Perplexity
Perplexity  Gemini
Gemini  Claude AI
Claude AI In today’s Artificial Intelligence (AI) era, AI is evolving rapidly, it’s almost everywhere, and there are so many LLMs present, and it’s not stopping here. We see new models coming every few months. From GPT to Claude and Gemini, DeepSeek, and Nvidia, it becomes challenging to determine which AI model performs best.
This is why AI, or you can say LLMs leaderboards comes handy.
Before all this, I was trying a script transformation from Python to C++, and I was comparing the performance. At the time, I used GPT-5, and it actually did a great job with performance. With that, I also tried with Claude Sonnet 4.5, which performed well, but it did not match the performance of the GPT-5 transformed code.
I was considering that these are the top companies in their field, so this is max I can get.
But later, I got to know that there is a leaderboard that shows which model is doing absolutely great in which type of work. So I checked there and tried the top models in a coding benchmark. There, I saw that Grok 4, Gemini 2.5 pro, along with GPT-5 and Claude sonnet, are in the top list, so I tried the same thing with Grok 4 and Gemini 2.5 pro. After seeing the results, I was amazed by Grok 4’s performance. I never expected it to work this well. Although Gemini 2.5 Pro ranks at the top overall, Grok 4 really impressed me.
At that point, I thought of sharing some leaderboards, so others can also check and get help from them.
In this blog, we will explore the Top 5 AI Leaderboards in 2026. In terms of how they work, and how they can help you choose the best AI model as per your task.
Wait, But what exactly is an AI Leaderboard?
Leaderboards are something that rank models based on benchmarks like reasoning ability, coding performance, mathematics, and real-world usage. It gives developers, founders, researchers, or anyone who is using AI for their work an objective way to compare models.
Think like a sports ranking. Instead of ranking players or teams, it ranks machine learning models based on standardised tests known as benchmarks.
These benchmarks evaluate how well an AI performs in areas such as:
- Reasoning ability
- Coding skills
- Mathematics problem solving
- Language understanding
- Real-world task completion
Leaderboard helps developers or AI users to quickly identify which models perform best for their use case.
Let’s see how AI models are evaluated
AI leaderboards rely on benchmark datasets to test LLMs’ performance.
Common Benchmarks -
- MMLU (Massive Multitask Language Understanding): Measures general knowledge and reasoning ability.
- Humanity's Last Exam (HLE): The new “final frontier” of benchmarks, featuring 2500 expert-level, much broader and harder benchmark covering many subjects, It’s meant to test frontier-level reasoning ability.
- GSM8K: Grade-school math word problems. Sounds easy, but it's notoriously tricky for language models.
- HumanEval: The coding test. In this AI is asked to write functional software programs from scratch.
- GPQA (Google-Proof Q&A): PhD-level science questions. These are questions so hard that even human experts with access to Google struggle to answer them quickly.
- SWE-bench: Real-world software engineering. Models have to resolve actual, historical GitHub issues.
Each leaderboard combines multiple benchmark scores to produce an overall ranking. There are many more benchmarks that the leaderboard combines.
Top 5 AI Leaderboards
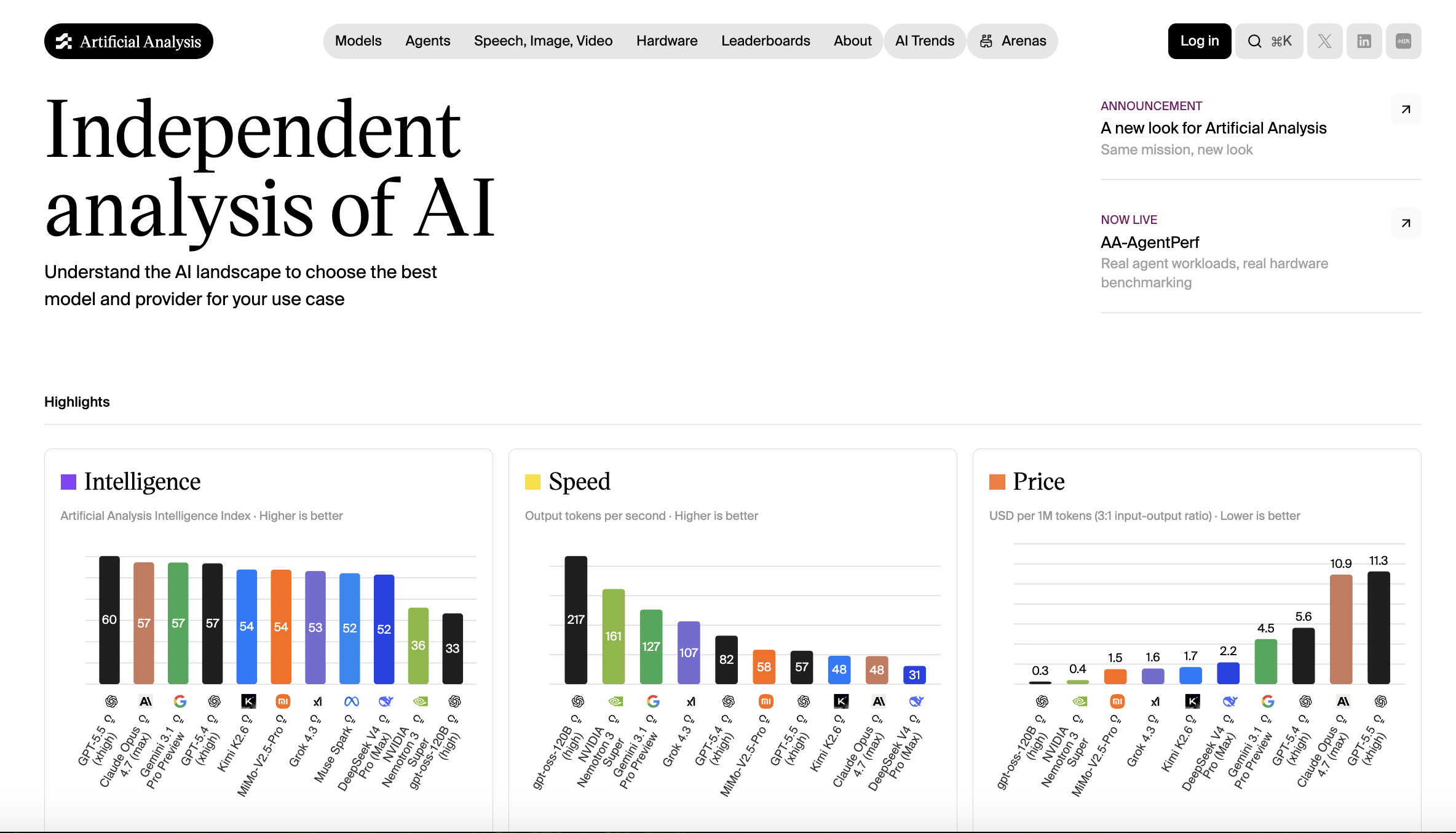
1. Artificial Analysis
This is one of my favourites. If you want to see the big picture, you can start from here. Artificial Analysis is probably the most comprehensive dashboard out there right now. They take a bunch of different benchmark scores and combine them into a single "Intelligence Index”, making it easier to compare with different models. It’s like a go-to place before you start.
Why it stands out
- It combines multiple benchmarks into one score
- Frequently updated rankings
- Covers major models like GPT, Claude, Gemini, Nvidia
- Easy-to-read interface
Screenshot of the Intelligence, speed, and pricing Index ranking page.
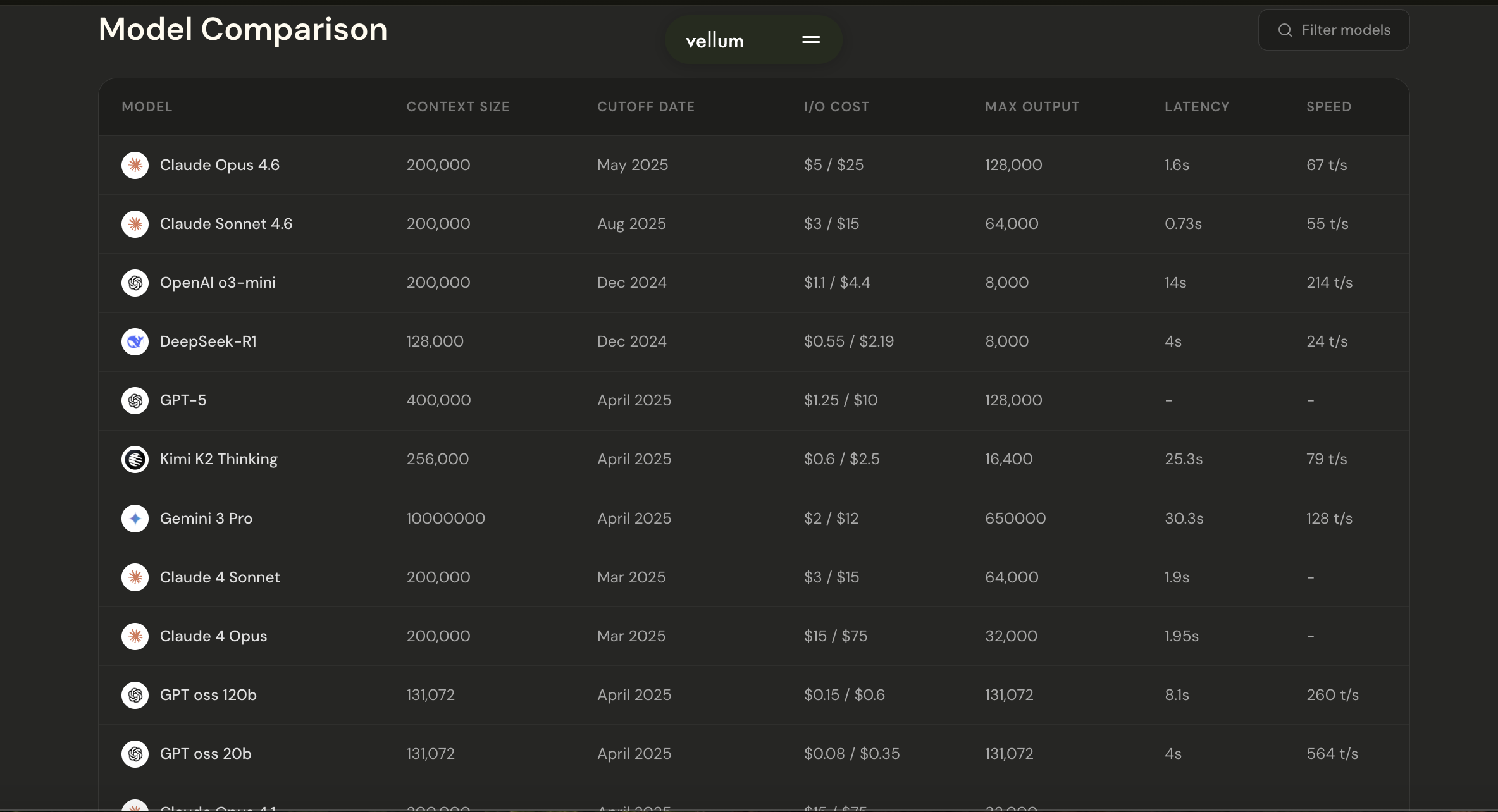
2. Vellum AI Leaderboard
The Vellum AI Leaderboard mainly focuses on real-world LLM performance rather than outdated academic benchmarks. This leaderboard helps developers to understand which models perform best in production environments. Also helps in comparing the different models with the Context window, cost, speed, and more.
Why it stands out
- It filters outdated benchmarks
- Focuses heavily on latency, context windows, and real-world utility
- Useful for developers building applications
- Side by side comparison
Screenshot of the Leaderboard comparison table UI.
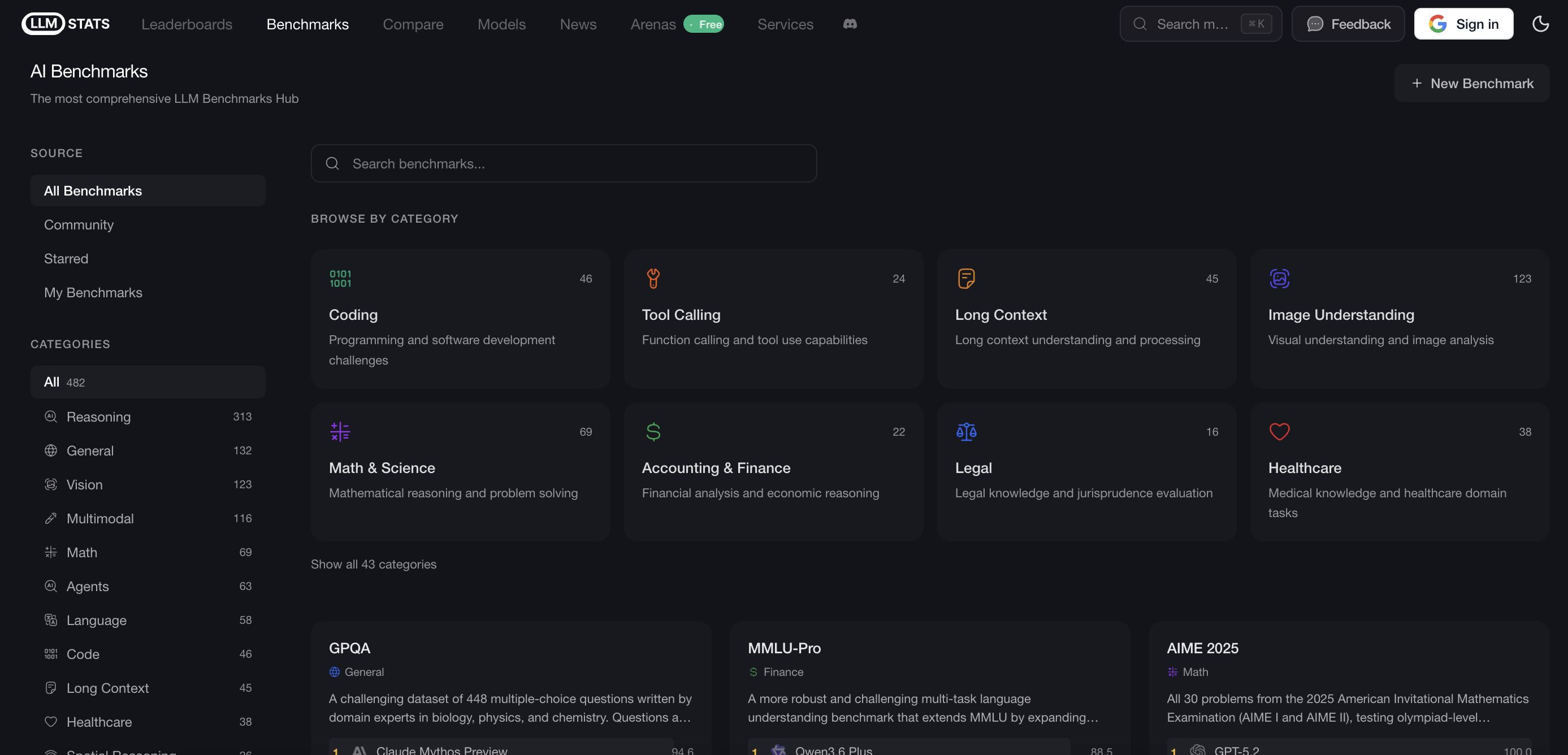
3. LLM Stats
LLM Stats is basically an aggregator. Instead of running their own isolated tests, they pull benchmark data from all over the web to give you a centralized hub.
Why it stands out
- Covers multiple AI domains
- Great for deep-dive research
- Gives you a bird's-eye view of the whole ecosystem
Screenshot of the Benchmark category dashboard.
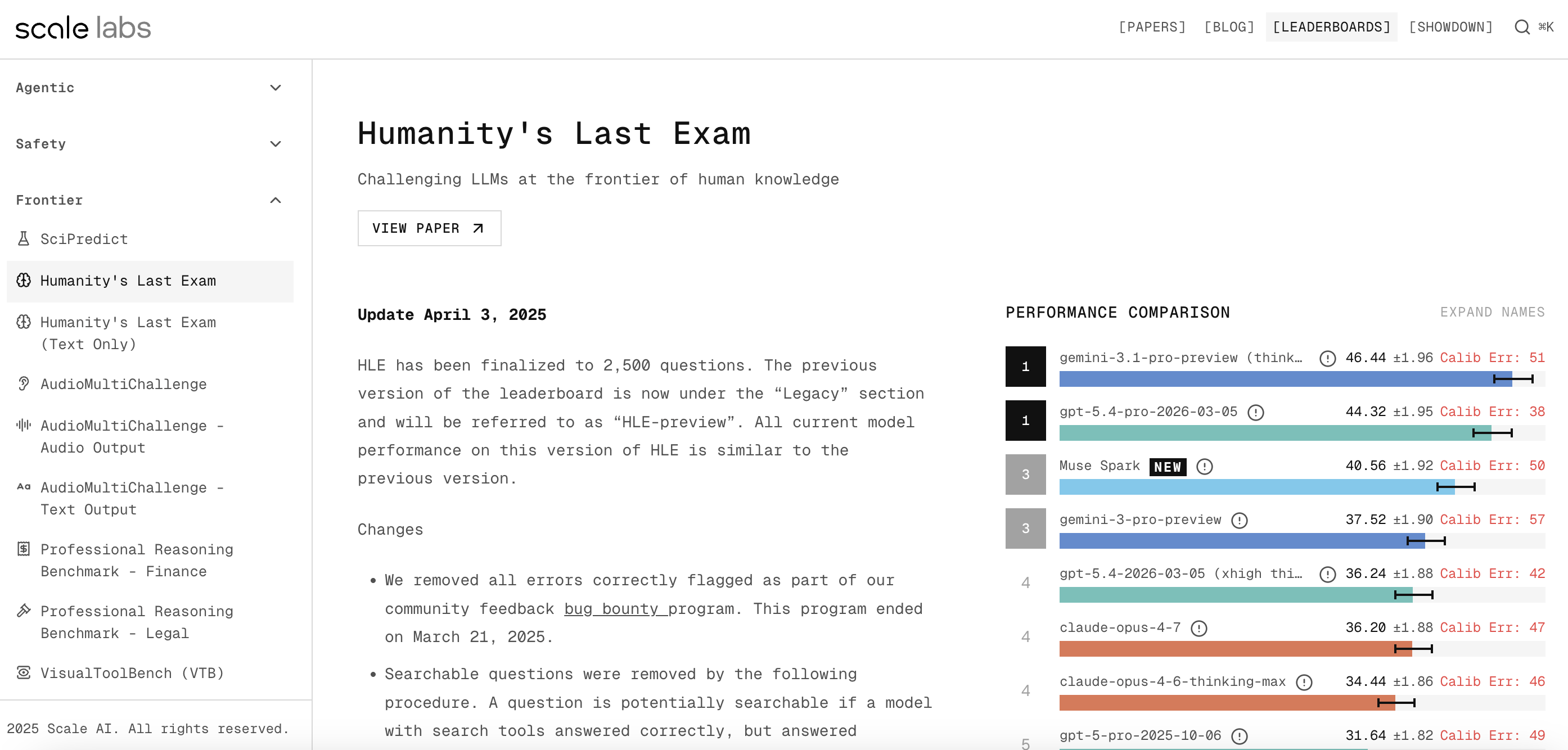
4. Scale AI (SEAL Leaderboards)
I have not personally used it, but per research, the SEAL Leaderboard is mostly used by Enterprise companies. They look at the Scale leaderboard before they spend millions on AI. Their SEAL (Scale Evaluation and Analysis of LLMs) leaderboards are rigorous, focusing heavily on advanced reasoning and instruction-following.
Why it stands out
- Incredibly tough grading curve
- Highly trusted by Fortune 500 enterprises
- Great for testing absolute frontier capabilities
Screenshot of the Reasoning benchmark comparison chart.
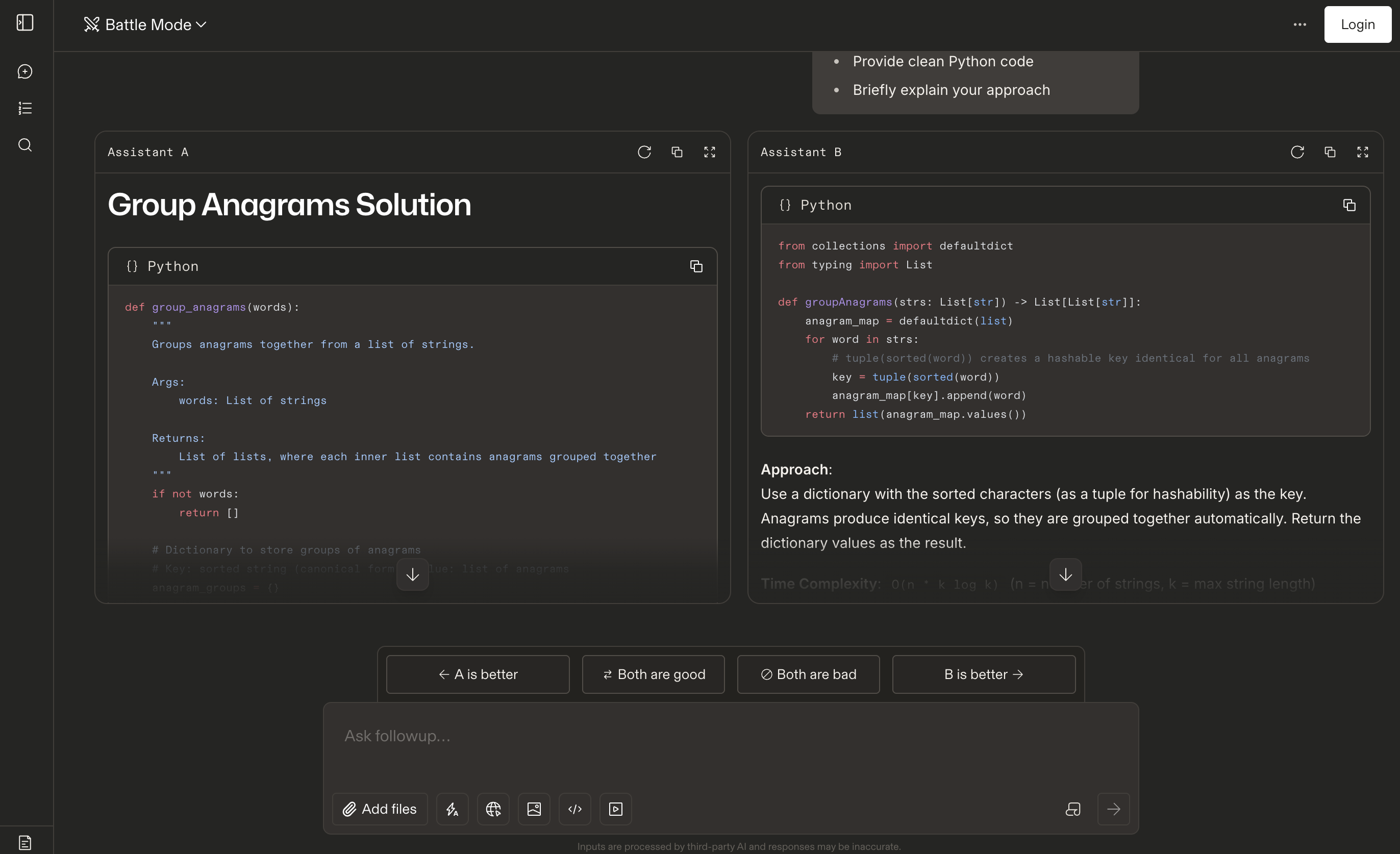
5. Chatbot Arena (LMSYS)
I personally feel this leaderboard is different from others as it ranks models based on human preference. Where users come to the website, ask questions, and vote for one Assistant (model) based on the model’s response
Why it stands out
- Based on real human feedback
- Reflects real-world usefulness
- Continuously updated
Screenshot of the Battle comparison interface.
Comparison Table
| Leaderboard | Best For | Updated Frequently | Ease of Use |
| Artificial Analysis | Overall ranking | Yes | Easy |
| Vellum | Real-world performance | Yes | Medium |
| LLM Stats | Research | Yes | Medium |
| Scale AI | Advanced reasoning | Yes | Medium |
| Chatbot Arena | Human preference | Yes | Easy |
Why AI Leaderboards Matter
If you’re just using AI for simple tasks like writing an email, correcting grammar, or asking for a joke, then you probably don’t need to stress about it. But if you are a developer, founder, tech leader, or building a product, then it’s non-negotiable.
Here are the points on how leaderboards help.
- Choosing the best AI model as per your need
- Compares performance vs cost vs context size
- Tracking progress in AI capabilities
- Selecting models for coding assistants
- Identifying strengths and weaknesses of each model
They act as a starting point when evaluating AI technologies.
Limitations of AI Leaderboards
Leaderboards are becoming a powerful method for evaluating and comparing models, but it’s not perfect, not at the moment, at least.
- Benchmarks may not capture creativity
- Frequent changes in ranking
- Some models are optimize specifically for benchmarks
- Real-world performance may vary depending on task
Therefore, leaderboards should be used as guidance rather than the absolute truth.
Conclusion
AI leaderboards provide valuable insights into models’ performance and capabilities. Whether you are a developer, researcher, or business owner, these tools can help you make decisions when selecting AI technologies.
Keeping an eye on the latest AI leaderboards can give you a good sense of where things stand as technology progresses.













