

 ChatGPT
ChatGPT  Perplexity
Perplexity  Gemini
Gemini  Claude AI
Claude AI A practical guide to building bi-directional data replication for distributed systems with intermittent connectivity - using CDC, Kafka, and MirrorMaker.
The Challenge: When Connectivity Can't Be Trusted
Imagine you're running infrastructure across multiple locations. Your central data center has rock-solid internet connectivity, but your remote sites? Not so much. They go offline unpredictably, sometimes for minutes, sometimes for hours.
Here's the catch: both sides generate business-critical data that needs to stay in sync.
Your Central Data Center manages master data, configurations, catalog updates, and user information. Your Remote Sites process transactions, local operations, and real-time activity. Each side needs what the other produces. And the data keeps flowing even when the network doesn't.
We built this a POC with a focused goal: make configurable bi-directional data replication work between a Central Data Center and Remote Sites using open source technology to avoid vendor lock-in and with no modification to existing application code.
The Constraints We Faced
This wasn't a greenfield project. We had to work within some hard boundaries:
- Bi-directional sync required - Not just pushing data one way. Changes happen on both sides and need to flow in both directions. We needed to capture data changes from both sides and consolidate them, rather than simply overwriting data with a timestamp.
- Intermittent connectivity - Remote sites go offline without warning. We can't assume an always-on network.
- No backend code changes - Existing applications with relational databases and stored procedures. Database migration wasn't feasible.
- No data loss - Every transaction matters. Losing records during a network outage isn't acceptable.
- Legacy replication tools were going end-of-support. Vendor lock-in and limited visibility into failures made them increasingly risky.
- Migrating to another database: A lot of things were built on the database, such as stored procedures, so migrating to another database was not an option, since that would require rewriting the application layer.
Why Traditional Approaches Fall Short
We evaluated the usual suspects:
Database-native replication assumes always-on connectivity. When the network drops, you're left with manual intervention and potential data conflicts.
Application-level sync requires code changes in every service. It's hard to maintain consistency across multiple data sources, and it doesn't scale well.
The insight that changed our approach: we needed something that works at the infrastructure level - invisible to applications, resilient to network issues, and capable of handling bi-directional flow without touching existing code.
The Architecture: CDC + Event Streaming + Cross-Site Mirroring
Our solution combines three core ideas:
- Capture changes at the database level using Change Data Capture (CDC) - no application modifications needed
- Stream changes through Kafka - durable, handles disconnects gracefully
- Mirror streams between sites using MirrorMaker - bi-directional, resumes automatically
Design Principles
Before diving into components, here's what guided our decisions:
- Non-invasive: Infrastructure-only changes. No modifications to application code or database schemas required.
- Bi-directional: Data flows both ways - Central to Remote and Remote to Central.
- Offline-resilient: Network partitions are expected, not exceptional.
- Open-source: No vendor lock-in. Cloud-agnostic and portable.
- Observable: Full visibility into replication health and failures.
High-Level Flow
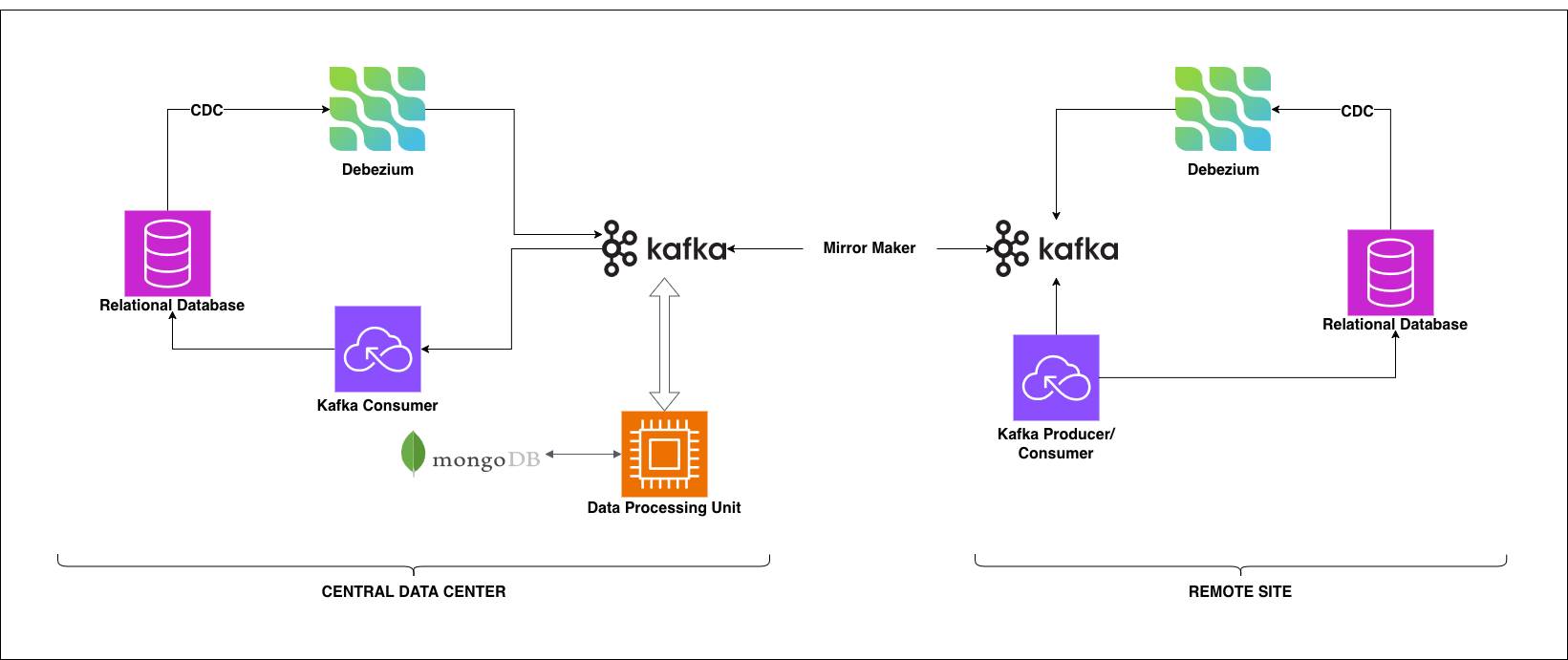
The same flow works in reverse for Remote-to-Central replication.
The Building Blocks
Let's break down each component and its role.
Capture & Produce: CDC + Debezium
Change Data Capture (CDC) is enabled at the database level. It tracks every INSERT, UPDATE, and DELETE operation without requiring any application changes. The key advantage: it works transparently with existing stored procedures and has minimal performance overhead.
Debezium reads the CDC logs and transforms changes into structured JSON events. It's fully open-source, integrates natively with Kafka, and handles schema evolution automatically. We deploy Debezium on Kubernetes at both the Central DC and Remote Sites.
The combination gives us complete visibility into what's changing in our databases - without touching a single line of application code.
Stream & Buffer: Apache Kafka
Kafka is the backbone of this architecture. It serves as a durable event store that retains messages even during network outages.
At the Central Data Center, we use a managed Kafka service to reduce operational overhead. At Remote Sites, we run self-hosted Kafka on Kubernetes - necessary since these sites need to operate independently when disconnected.
The critical feature: Kafka retains events until they're successfully processed. When a remote site goes offline, events queue up. When it reconnects, processing resumes exactly where it left off.
Process & Route: Spark + MongoDB
This isn't just pass-through replication. Real-world scenarios demand a processing layer.
We use Spark/PySpark for:
- Filtering: Selecting relevant fields for replication (not everything needs to sync)
- Conflict detection: Identifying when the same record was modified at both sites
- Edge case handling: Managing delayed logs, timing issues, and ordering problems
- Routing: Directing events to destination-specific Kafka topics
- Custom Rules: Allows handling special edge cases involving things like syncing the dependent tables first, tracking data conflicts, and allowing manual data merges, etc
MongoDB serves as the metadata store. It consolidates data from both sides, tracks conflict resolution decisions, and provides a fallback for recovery scenarios. Having a central view of what's happening on both sides proved invaluable for debugging.
Mirror & Sync: MirrorMaker 2
MirrorMaker is the hero component for intermittent connectivity.
It mirrors Kafka topics between the Central DC and Remote Sites. When the network is available, events flow. When it drops, MirrorMaker simply waits. When connectivity returns, it resumes from the last successful offset - no data loss, no manual intervention.
This automatic resume capability is what makes the entire architecture work for unreliable networks.
Consume & Apply: KNative
On the receiving end, KNative provides a serverless approach to consuming Kafka events.
It polls specific Kafka topics, processes the events, and writes them to the target database. The key property: idempotency. Events can be safely replayed without causing duplicate records. This matters when recovering from failures or processing backlogs after a reconnection.
Running on Kubernetes, KNative scales automatically based on event volume and is easier to manage than traditional consumer applications.
Monitor: Prometheus
Prometheus handles monitoring and alerting across the entire pipeline. We track replication lag, event throughput, consumer health, and error rates.
Visibility was non-negotiable. Without it, you're blind to problems until they become critical.
Following the Data: A Quick Example
Let's trace a single record update through the system.
Scenario: A database record is updated at the Central Data Center and needs to reach all Remote Sites.
- Application updates the record in the Central DC's relational database
- CDC captures the change logged at the database level
- Debezium reads the CDC log and produces a JSON event to Kafka
- Processing layer receives the event - filters fields, checks for conflicts against MongoDB metadata, routes to the appropriate destination kafka topic
- MirrorMaker picks up the event - if the network is available, it mirrors immediately; if not, it waits
- Network becomes available - MirrorMaker sends the event to the Remote Site's Kafka cluster
- KNative functions consumes the event from the local Kafka
- The record is applied to the Remote Site's database
The reverse flow works identically. A transaction recorded at a Remote Site follows the same path back to the Central DC.
Total latency when connected: sub-second. When disconnected, events queue up and flow through once connectivity returns, maintaining order.
Handling Edge Cases
A replication system is only as good as its handling of failure scenarios. Here's how we address the common ones:
| Edge Case | How We Handle It |
|---|---|
| Network drops mid-sync | Kafka buffers all events locally. MirrorMaker tracks the last successful offset and resumes exactly where it stopped. No manual intervention required. |
| Same record modified at both sites | The processing layer detects conflicts using MongoDB metadata. Default resolution: timestamp-based (latest write wins). Custom rules can be configured for specific tables. All conflicts are logged for audit. |
| Remote site reconnects with hours of backlog | MirrorMaker replays events in order. The processing layer maintains sequencing. System catches up automatically. |
| Database schema changes | Debezium tracks schema evolution. Backward-compatible changes propagate automatically through the pipeline. Breaking changes require coordinated deployment. |
Key Takeaways
After implementing this system, here's what we learned:
CDC gives you visibility without touching application code. Understanding what changes at the database level is foundational. Without it, you're either modifying applications or flying blind.
Kafka is your safety net. Trust it to handle offline scenarios. Its durability and offset tracking are what make intermittent connectivity manageable rather than catastrophic.
Conflict resolution needs business input. Technical defaults (like "latest write wins") aren't enough for every table. Some data requires custom rules. Build the flexibility early.
Monitor from day one. Prometheus wasn't an afterthought - it was part of the initial deployment. Replication failures are silent until they're not. You need visibility before problems become emergencies.
When to Use This Pattern
This architecture fits well when you have:
- Distributed infrastructure with unreliable connectivity
- Bi-directional data sync requirements
- Legacy databases you can't (or don't want to) modify
- Need for an open-source, cloud-agnostic solution
It's probably overkill for single-site deployments or simple one-way replication where simpler tools exist.
Conclusion
Data doesn't stop flowing when the network does. Transactions happen. Business continues.
By working at the infrastructure level, we built a system that does exactly that.
Change Data Capture (CDC) tracks database changes as they happen, Kafka safely buffers them, MirrorMaker syncs data across sites, and Spark processes everything while handling the messy edge cases that inevitably show up in distributed systems.
The entire stack is open-source. There's no vendor lock-in. It runs on any cloud or on-premise infrastructure. And most importantly, it handles the inevitable: networks fail, sites disconnect, and data keeps flowing anyway.
Your replication strategy should do the same.
Technologies used: Debezium, Apache Kafka, MirrorMaker 2, Spark/PySpark, MongoDB, KNative, Prometheus, Kubernetes












